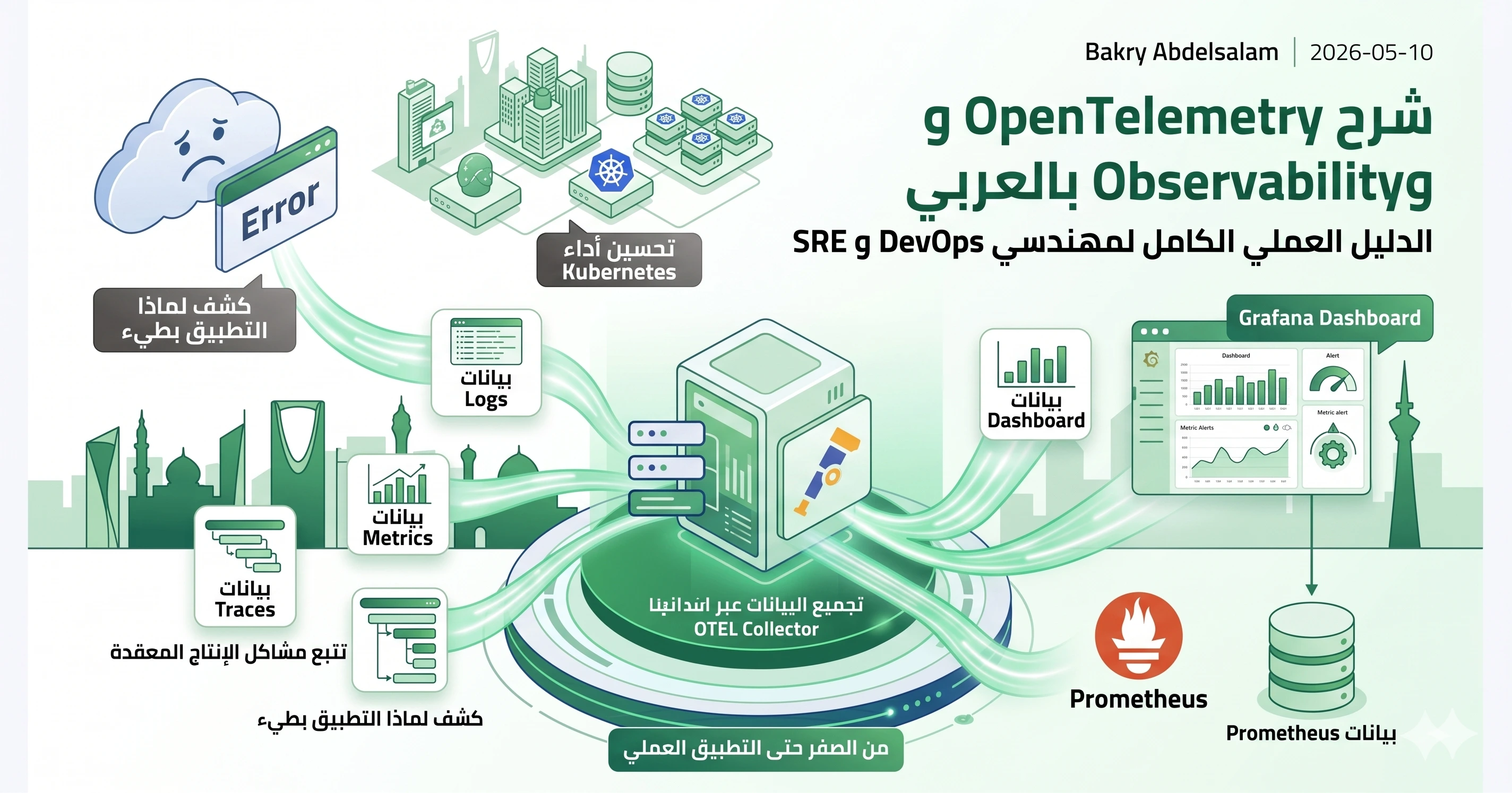
في الأنظمة الحديثة لم يعد السؤال المهم هو: هل السيرفر يعمل أم لا؟ السؤال الحقيقي أصبح: لماذا التطبيق بطيء؟ أين حدث الخطأ؟ أي خدمة سببت المشكلة؟ ولماذا فشل طلب المستخدم رغم أن كل السيرفرات تظهر أنها تعمل؟
هنا يظهر مفهوم Observability أو القابلية للملاحظة. ومع انتشار Microservices و Kubernetes و Cloud Native و Serverless، أصبح من الصعب فهم ما يحدث داخل النظام بالاعتماد فقط على Logs تقليدية أو Dashboard بسيطة.
لهذا ظهر OpenTelemetry كواحد من أهم المشاريع في عالم DevOps و SRE و Cloud Engineering. في هذا الدليل سنشرح Observability و OpenTelemetry بشكل عملي: Logs و Metrics و Traces و Collector و OTLP، وكيف تربط ذلك مع Prometheus و Grafana و Kubernetes.
لمن هذا المقال؟
هذا الدليل مناسب لك إذا كنت:
- مهندس DevOps أو SRE أو Platform Engineer.
- Backend Developer يريد فهم مشاكل Production بعمق.
- تعمل مع Kubernetes أو Docker أو Microservices.
- تستخدم Prometheus أو Grafana وتريد ربطها بتجربة Observability كاملة.
- تريد فهم tracing و metrics و logs بطريقة عملية.
لا تحتاج أن تكون خبيرا. سنبدأ من الأساسيات ثم ننتقل تدريجيا إلى التصميم العملي.
المشكلة التي يحلها Observability
تخيل أن لديك تطبيق تجارة إلكترونية مكونا من:
- Frontend
- API Gateway
- Auth Service
- Orders Service
- Payment Service
- PostgreSQL
- Redis
- Message Queue
أرسل مستخدم طلب شراء، لكن العملية فشلت. في الطريقة التقليدية قد تسأل: هل API يعمل؟ هل قاعدة البيانات متاحة؟ هل هناك Error في Logs؟ هل CPU مرتفع؟
لكن أحيانا كل شيء يبدو سليما، ومع ذلك الطلب فشل. ربما Payment Service استغرق 8 ثوان بدلا من 200ms. ربما Redis يحتوي بيانات قديمة. ربما Deployment جديد غيّر environment variable. وربما خدمة خارجية أصبحت بطيئة.
هنا تحتاج أن ترى رحلة الطلب كاملة داخل النظام، وهذا هو جوهر Observability.
ما معنى Observability؟
Observability هي قدرة الفريق على فهم الحالة الداخلية للنظام من خلال البيانات التي يخرجها النظام.
بمعنى أبسط: Observability تعني أن تستطيع طرح أسئلة جديدة وغير متوقعة على النظام، وتحصل على إجابات واضحة من البيانات المتاحة.
هي ليست Dashboard فقط، وليست Logs فقط، وليست Alerts فقط. هي طريقة لفهم سلوك النظام في Production.
الفرق بين Monitoring و Observability
كثير من الناس يخلطون بين Monitoring و Observability.
Monitoring يجيب غالبا على أسئلة معروفة مسبقا:
- هل السيرفر يعمل؟
- هل CPU أعلى من 80%؟
- هل عدد الأخطاء زاد؟
- هل الخدمة ترجع status code 500؟
أما Observability فتساعدك على فهم مشاكل لم تكن تعرف أنها ستحدث:
- لماذا endpoint معين بطيء فقط بعد آخر deployment؟
- لماذا بعض المستخدمين فقط يعانون من المشكلة؟
- أي microservice تسبب في فشل transaction كاملة؟
- هل البطء من الكود أم قاعدة البيانات أم خدمة خارجية؟
| المقارنة | Monitoring | Observability |
|---|---|---|
| الهدف | معرفة هل النظام يعمل | فهم لماذا يتصرف النظام بهذه الطريقة |
| نوع الأسئلة | معروفة مسبقا | جديدة وغير متوقعة |
| الأدوات | Metrics و Alerts | Logs و Metrics و Traces مع Context |
| مناسب لـ | مشاكل واضحة | أنظمة معقدة وموزعة |
الأعمدة الأساسية في Observability
غالبا تسمع عن ثلاثة أعمدة رئيسية:
- Logs
- Metrics
- Traces
القيمة الحقيقية لا تأتي من كل نوع وحده، بل من الربط بينهم.
Logs
الـ Logs هي سجلات نصية توضح أحداثا حدثت داخل التطبيق.
مثال بسيط:
2026-05-10T10:15:22Z ERROR payment-service Failed to charge customer order_id=98421 reason=card_declinedالـ Logs مفيدة لمعرفة تفاصيل حدث معين: سبب exception، user_id، order_id، أو خطوات تنفيذ request.
المشكلة أن Logs قد تتحول إلى فوضى إذا لم تكن منظمة. هذا Log ضعيف:
Something went wrongأما هذا Log فهو أفضل لأنه يحتوي على context:
{
"level": "error",
"service": "payment-service",
"environment": "production",
"trace_id": "9f4b7c2e1a",
"span_id": "a71d9c3",
"order_id": "98421",
"user_id": "5821",
"message": "Failed to charge customer",
"reason": "card_declined"
}Metrics
الـ Metrics هي أرقام قابلة للقياس عبر الزمن.
أمثلة:
- عدد الطلبات في الثانية.
- متوسط زمن الاستجابة.
- نسبة الأخطاء.
- استهلاك CPU و Memory.
- عدد الرسائل في Queue.
- عدد failed payments.
مثال metric:
http_requests_total{service="orders", method="POST", status="500"} 42أشهر أنواع Metrics:
- Counter: رقم يزيد فقط، مثل عدد الطلبات أو الأخطاء.
- Gauge: رقم يزيد وينقص، مثل الذاكرة الحالية أو عدد الاتصالات.
- Histogram: يقيس توزيع القيم، ومفيد جدا لقياس latency.
- Summary: يحسب إحصاءات مثل quantiles، لكن في بيئات كثيرة يفضل Histogram لأنه أسهل في التجميع.
Traces
الـ Traces هي العنصر الذي يغير طريقة فهم الأنظمة الموزعة. Trace واحد يوضح رحلة request داخل عدة خدمات.
مثال لطلب شراء:
Frontend
-> API Gateway
-> Auth Service
-> Orders Service
-> Inventory Service
-> Payment Service
-> Notification Serviceكل خطوة داخل هذه الرحلة تسمى Span، والرحلة كاملة تسمى Trace.
مثال مبسط:
Trace ID: abc123
POST /checkout 1200ms
├── auth.validate_token 40ms
├── orders.create_order 120ms
├── inventory.reserve_items 200ms
├── payment.charge_customer 780ms
└── notifications.send_email 60msمن هذا المثال نعرف بسرعة أن أبطأ جزء هو payment.charge_customer.
العلاقة بين Logs و Metrics و Traces
القوة الحقيقية تظهر عندما تربط الثلاثة معا:
- Alert يخبرك أن error rate زاد.
- Metrics توضح أن المشكلة في endpoint
/checkout. - Traces توضح أن
payment-serviceبطيئة. - Logs المرتبطة بنفس
trace_idتوضح أن مزود الدفع يرجع timeout.
بهذا تنتقل من “هناك مشكلة في النظام” إلى “طلبات checkout تفشل لأن payment-service تستقبل timeout من مزود الدفع الخارجي، والتأثير بدأ بعد الساعة 10:05”.
ما هو OpenTelemetry؟
OpenTelemetry أو OTel هو framework و toolkit مفتوح المصدر ومحايد من ناحية الشركات، هدفه تسهيل توليد وجمع وتصدير بيانات telemetry مثل:
- Traces
- Metrics
- Logs
إلى أنظمة Observability مختلفة.
قبل OpenTelemetry، كان كل vendor يملك SDK أو agent أو format مختلف. هذا يؤدي إلى Vendor Lock-in. أما OpenTelemetry فيوفر standard موحدا: جهز التطبيق مرة واحدة، ثم أرسل البيانات إلى Grafana Tempo أو Jaeger أو Prometheus أو Datadog أو New Relic أو Elastic أو أي backend يدعم OTLP.
الفكرة الأساسية:
Instrument once, export anywhere.هل OpenTelemetry بديل لـ Prometheus أو Grafana؟
لا. OpenTelemetry ليس Dashboard وليس قاعدة بيانات Metrics وليس بديلا مباشرا لـ Grafana.
| الأداة | الدور |
|---|---|
| OpenTelemetry SDK | توليد telemetry من التطبيق |
| OpenTelemetry Collector | استقبال ومعالجة وتصدير البيانات |
| Prometheus | تخزين واستعلام Metrics غالبا |
| Grafana | عرض Dashboards |
| Jaeger / Tempo | تخزين وتحليل Traces |
| Loki | تخزين Logs |
| Alertmanager | إدارة التنبيهات |
OpenTelemetry يعمل مع هذه الأدوات ولا يلغيها.
مكونات OpenTelemetry الأساسية
OpenTelemetry يتكون من عدة أجزاء:
- API: الواجهة التي يستخدمها الكود لإنشاء traces أو metrics.
- SDK: التطبيق العملي للـ API، وهو المسؤول عن جمع البيانات وإرسالها.
- Instrumentation Libraries: مكتبات جاهزة لإضافة observability تلقائيا إلى Express و Fastify و Spring Boot و Django و Flask و PostgreSQL و Redis و Kafka وغيرها.
- Exporters: ترسل البيانات إلى جهة خارجية مثل OTLP أو Prometheus أو Jaeger.
- Collector: خدمة مستقلة تستقبل telemetry، تعالجها، ثم ترسلها إلى backend مناسب.
ما هو OpenTelemetry Collector؟
الـ Collector هو خدمة مستقلة تعمل كوسيط بين التطبيقات وأنظمة Observability.
الشكل العام:
Application
|
| OTLP
v
OpenTelemetry Collector
|
|----> Prometheus / Mimir
|----> Jaeger / Tempo
|----> Loki / Elastic
|----> Vendor مثل Datadog أو New Relicاستخدام Collector في Production أفضل من إرسال كل تطبيق مباشرة إلى backend، لأنه يعطيك:
- تقليل الاعتماد على vendor.
- معالجة البيانات مركزيا.
- حذف بيانات حساسة.
- إضافة attributes مثل environment و cluster name.
- تطبيق sampling.
- إرسال نسخة من البيانات لأكثر من مكان.
مكونات Collector
يتكون Collector من أربعة مفاهيم أساسية:
- Receivers
- Processors
- Exporters
- Pipelines
Receivers
الـ Receiver يستقبل البيانات.
receivers:
otlp:
protocols:
grpc:
http:هذا يعني أن Collector سيستقبل OTLP عبر gRPC و HTTP.
Processors
الـ Processor يعالج البيانات قبل إرسالها.
processors:
memory_limiter:
limit_mib: 512
spike_limit_mib: 128
check_interval: 5s
batch:batch يحسن الأداء لأنه يرسل البيانات على دفعات. و memory_limiter يحمي Collector من استهلاك memory بشكل زائد وقت ارتفاع traffic.
Exporters
الـ Exporter يرسل البيانات إلى destination.
exporters:
otlp/tempo:
endpoint: tempo:4317
tls:
insecure: true
debug:
verbosity: basicPipelines
الـ Pipeline يربط receiver و processor و exporter.
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp/tempo, debug]مثال كامل لملف Collector
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
memory_limiter:
check_interval: 5s
limit_mib: 512
spike_limit_mib: 128
batch:
resource:
attributes:
- key: deployment.environment
value: production
action: upsert
- key: service.namespace
value: ecommerce
action: upsert
exporters:
debug:
verbosity: basic
otlp/tempo:
endpoint: tempo:4317
tls:
insecure: true
prometheus:
endpoint: 0.0.0.0:9464
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, resource, batch]
exporters: [otlp/tempo, debug]
metrics:
receivers: [otlp]
processors: [memory_limiter, resource, batch]
exporters: [prometheus, debug]
logs:
receivers: [otlp]
processors: [memory_limiter, resource, batch]
exporters: [debug]ما هو OTLP؟
OTLP اختصار لـ OpenTelemetry Protocol، وهو البروتوكول القياسي لنقل telemetry data.
غالبا يستخدم:
OTLP/gRPC: 4317
OTLP/HTTP: 4318مثال:
http://otel-collector:4318OTLP مهم لأنه يعطيك طريقة موحدة لإرسال البيانات من التطبيقات إلى Collector، ثم يقرر Collector أين يرسلها.
أهم Resource Attributes
الـ Resource يصف الكيان الذي أنتج telemetry.
اهتم بهذه attributes:
service.name
service.version
service.namespace
deployment.environment
k8s.cluster.name
k8s.namespace.name
k8s.pod.name
cloud.provider
cloud.regionبدونها ستصبح قراءة traces و metrics صعبة جدا في بيئة كبيرة.
مثال:
{
"service.name": "orders-service",
"service.version": "1.7.3",
"service.namespace": "ecommerce",
"deployment.environment": "production",
"k8s.cluster.name": "prod-cluster-01"
}Semantic Conventions
Semantic Conventions هي أسماء ومعاني موحدة للـ attributes.
بدلا من أن يسمي كل فريق status code بطريقة مختلفة، توفر OpenTelemetry أسماء موحدة مثل:
http.response.status_codeهذا يساعدك على بناء dashboards عامة، البحث بسهولة، الربط بين الخدمات، وتقليل الفوضى في البيانات.
مثال Node.js مع Express
تثبيت الحزم:
npm install @opentelemetry/api
npm install @opentelemetry/sdk-node
npm install @opentelemetry/auto-instrumentations-node
npm install @opentelemetry/exporter-trace-otlp-httpملف telemetry.js:
const { NodeSDK } = require("@opentelemetry/sdk-node");
const {
getNodeAutoInstrumentations
} = require("@opentelemetry/auto-instrumentations-node");
const {
OTLPTraceExporter
} = require("@opentelemetry/exporter-trace-otlp-http");
const sdk = new NodeSDK({
serviceName: "orders-service",
traceExporter: new OTLPTraceExporter({
url: "http://localhost:4318/v1/traces"
}),
instrumentations: [getNodeAutoInstrumentations()]
});
sdk.start();تشغيل التطبيق:
node -r ./telemetry.js app.jsتطبيق Express بسيط:
const express = require("express");
const app = express();
app.get("/checkout", async (req, res) => {
await new Promise((resolve) => setTimeout(resolve, 300));
res.json({ message: "Checkout completed" });
});
app.get("/error", () => {
throw new Error("Something failed");
});
app.listen(3000, () => {
console.log("Server running on port 3000");
});مع auto-instrumentation سيبدأ OpenTelemetry في التقاط HTTP requests تلقائيا.
متى تضيف Span يدوي؟
Auto-instrumentation ممتاز كبداية، لكنه لا يعرف business logic.
أضف spans يدوية للعمليات المهمة مثل:
- create_order
- process_payment
- reserve_inventory
- send_invoice
- calculate_shipping
- validate_coupon
مثال:
const opentelemetry = require("@opentelemetry/api");
const tracer = opentelemetry.trace.getTracer("orders-service");
async function createOrder(orderId) {
return tracer.startActiveSpan("create_order", async (span) => {
try {
span.setAttribute("order.id", orderId);
span.setAttribute("business.operation", "checkout");
await saveOrderToDatabase(orderId);
span.setStatus({ code: opentelemetry.SpanStatusCode.OK });
return true;
} catch (error) {
span.recordException(error);
span.setStatus({
code: opentelemetry.SpanStatusCode.ERROR,
message: error.message
});
throw error;
} finally {
span.end();
}
});
}لا تضف span لكل function صغيرة حتى لا تنتج noise كبير.
مثال Python مع Flask
تثبيت الحزم:
pip install opentelemetry-distro
pip install opentelemetry-exporter-otlp
pip install flaskتشغيل auto-instrumentation:
opentelemetry-bootstrap -a installثم:
OTEL_SERVICE_NAME=payments-service \
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318 \
OTEL_EXPORTER_OTLP_PROTOCOL=http/protobuf \
opentelemetry-instrument python app.pyتطبيق Flask:
from flask import Flask, jsonify
import time
app = Flask(__name__)
@app.route("/pay")
def pay():
time.sleep(0.2)
return jsonify({"status": "paid"})
@app.route("/fail")
def fail():
raise Exception("Payment provider timeout")
if __name__ == "__main__":
app.run(port=5000)OpenTelemetry مع Docker Compose
مثال محلي بسيط:
version: "3.9"
services:
app:
build: .
environment:
OTEL_SERVICE_NAME: orders-service
OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:4318
OTEL_EXPORTER_OTLP_PROTOCOL: http/protobuf
ports:
- "3000:3000"
depends_on:
- otel-collector
otel-collector:
image: otel/opentelemetry-collector-contrib:latest
command: ["--config=/etc/otelcol/config.yaml"]
volumes:
- ./otel-collector-config.yaml:/etc/otelcol/config.yaml
ports:
- "4317:4317"
- "4318:4318"
- "9464:9464"OpenTelemetry مع Prometheus
Prometheus يعمل غالبا بطريقة pull، أي يسحب metrics من endpoints.
هناك طريقتان شائعتان:
Prometheus Exporter
يجعل Collector يفتح endpoint تقرأ منه Prometheus.
exporters:
prometheus:
endpoint: 0.0.0.0:9464ثم في Prometheus:
scrape_configs:
- job_name: "otel-collector"
static_configs:
- targets: ["otel-collector:9464"]Prometheus Receiver
يجعل Collector نفسه يسحب metrics من endpoints.
receivers:
prometheus:
config:
scrape_configs:
- job_name: "node-app"
static_configs:
- targets: ["app:3000"]لو لديك Prometheus موجود بالفعل، غالبا اجعل Prometheus يسحب من Collector. لو تريد توحيد الجمع داخل Collector، استخدم Prometheus receiver.
OpenTelemetry مع Grafana
Grafana غالبا يستخدم لعرض البيانات، وليس لتجميعها بنفسه.
تصميم شائع:
OpenTelemetry SDK
|
v
OpenTelemetry Collector
|
|---- metrics ---> Prometheus أو Mimir
|---- traces ---> Tempo
|---- logs ---> Loki
|
v
Grafana Dashboardsهذا قريب من LGTM Stack:
- Loki للـ Logs.
- Grafana للعرض.
- Tempo للـ Traces.
- Mimir أو Prometheus للـ Metrics.
OpenTelemetry مع Kubernetes
في Kubernetes توجد أكثر من طريقة لنشر Collector:
- Deployment Mode: Collector مركزي يستقبل telemetry من كل الخدمات.
- DaemonSet Mode: Collector على كل Node، مناسب لجمع host metrics و pod logs.
- Sidecar Mode: Collector بجانب كل تطبيق داخل نفس Pod، ويعطي عزلا أكبر لكنه يزيد التعقيد.
تصميم Production شائع:
Application Pods
|
v
Agent Collector as DaemonSet
|
v
Gateway Collector as Deployment
|
v
Observability Backendمثال Service داخل Kubernetes:
apiVersion: v1
kind: Service
metadata:
name: otel-collector
namespace: observability
spec:
selector:
app: otel-collector
ports:
- name: otlp-grpc
port: 4317
targetPort: 4317
- name: otlp-http
port: 4318
targetPort: 4318ثم تجعل التطبيقات ترسل إلى:
http://otel-collector.observability.svc.cluster.local:4318أهم Environment Variables
كثير من SDKs تدعم environment variables موحدة:
OTEL_SERVICE_NAME=orders-service
OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4318
OTEL_EXPORTER_OTLP_PROTOCOL=http/protobuf
OTEL_RESOURCE_ATTRIBUTES=deployment.environment=production,service.version=1.2.0
OTEL_TRACES_EXPORTER=otlp
OTEL_METRICS_EXPORTER=otlp
OTEL_LOGS_EXPORTER=otlpفي Kubernetes:
env:
- name: OTEL_SERVICE_NAME
value: "orders-service"
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://otel-collector.observability.svc.cluster.local:4318"
- name: OTEL_EXPORTER_OTLP_PROTOCOL
value: "http/protobuf"
- name: OTEL_RESOURCE_ATTRIBUTES
value: "deployment.environment=production,service.version=1.2.0"Sampling في OpenTelemetry
في الأنظمة الكبيرة لا تستطيع دائما تخزين كل traces. لو لديك 50,000 requests per second، تخزين trace لكل request سيكون مكلفا.
Sampling يعني اختيار جزء من traces لتخزينه بدل كل شيء.
Head Sampling
يتم القرار في بداية trace.
ميزته أنه بسيط ويقلل البيانات مبكرا. عيبه أنك قد تفقد traces مهمة لأن القرار اتخذ قبل معرفة النتيجة.
Tail Sampling
يتم القرار بعد انتهاء trace أو بعد رؤية أجزاء كافية منه.
مثلا:
- خزّن كل traces التي فيها errors.
- خزّن كل traces التي latency فيها أعلى من 2 ثانية.
- خزّن نسبة صغيرة من traces الناجحة.
مثال:
processors:
tail_sampling:
decision_wait: 10s
num_traces: 50000
policies:
- name: errors-policy
type: status_code
status_code:
status_codes: [ERROR]
- name: latency-policy
type: latency
latency:
threshold_ms: 2000
- name: probabilistic-policy
type: probabilistic
probabilistic:
sampling_percentage: 10استراتيجية جيدة كبداية:
Errors: 100%
Slow requests > 2s: 100%
Successful requests: 5% إلى 20%Correlation: الربط بين Logs و Traces
من أهم ممارسات Observability أن تجعل Logs تحتوي على:
trace_id
span_idمثال:
{
"timestamp": "2026-05-10T12:30:10Z",
"level": "error",
"message": "Payment request failed",
"service.name": "payment-service",
"trace_id": "0af7651916cd43dd8448eb211c80319c",
"span_id": "b7ad6b7169203331",
"order_id": "ORD-9912"
}عندما ترى هذا الخطأ في Loki أو Elastic، يمكنك البحث بنفس trace_id داخل Tempo أو Jaeger.
RED Method و USE Method
RED Method مناسبة للخدمات والـ APIs:
- Rate: كم request في الثانية؟
- Errors: كم نسبة الطلبات الفاشلة؟
- Duration: ما زمن الاستجابة؟
Dashboard لأي API يجب أن يحتوي على request rate و error rate و p95/p99 latency و top slow endpoints.
USE Method مناسبة للبنية التحتية:
- Utilization: كم نسبة استخدام المورد؟
- Saturation: هل المورد مضغوط؟
- Errors: هل المورد ينتج أخطاء؟
استخدم RED للخدمات، و USE للسيرفرات والـ Nodes والـ Infrastructure.
أهم Dashboards
ابدأ بهذه dashboards:
- Dashboard لكل خدمة: request rate، error rate، p95 latency، top endpoints، deploy version، CPU/Memory، related traces.
- Dashboard للـ Kubernetes: pod restarts، pending pods، CrashLoopBackOff، node pressure، OOM kills.
- Dashboard للـ Collector: dropped spans، exporter failures، queue size، memory usage، restarts.
لا تنس مراقبة Collector نفسه لأنه قد يصبح نقطة اختناق إذا لم تراقبه.
SLI و SLO
SLI هو قياس حقيقي، مثل نسبة الطلبات الناجحة أو نسبة الطلبات التي تمت خلال أقل من 300ms.
SLO هو الهدف الذي تلتزم به داخليا.
مثال:
99.5% من طلبات checkout يجب أن تنجح خلال أقل من 500ms خلال 30 يوما.هذا يحول Observability من مجرد Dashboards إلى قرارات تشغيلية.
أفضل ممارسات OpenTelemetry في Production
- ابدأ بخدمة واحدة مهمة، لا تحاول instrument كل شيء من أول يوم.
- لا تجمع telemetry بلا هدف.
- اضبط
service.nameلكل خدمة. - أضف
deployment.environmentوservice.version. - اربط logs بالـ traces عبر
trace_idوspan_id. - استخدم
memory_limiterوbatchفي Collector. - راقب Collector نفسه.
- احذف البيانات الحساسة قبل التصدير.
- انتبه إلى high cardinality.
- استخدم sampling عند زيادة حجم البيانات.
High Cardinality
Cardinality تعني عدد القيم المختلفة لـ label أو attribute.
مثال جيد:
http.method = GET أو POSTمثال خطر:
user.id = 928391تجنب وضع هذه القيم كـ labels في metrics:
- user_id
- request_id
- session_id
- order_id
- full URL with query params
مثال سيئ:
http_requests_total{user_id="123456", endpoint="/orders/98421"} 1مثال أفضل:
http_requests_total{method="GET", route="/orders/:id", status="200"} 1أخطاء شائعة
- الاعتماد على Logs فقط.
- عدم ضبط Resource Attributes.
- عدم مراقبة Collector.
- إرسال كل شيء بدون Sampling.
- وضع user_id كـ metric label.
- عدم ربط logs بالـ traces.
- الاعتماد الكامل على auto-instrumentation بدون spans يدوية للعمليات المهمة.
خطة تطبيق OpenTelemetry في شركة حقيقية
المرحلة الأولى: التأسيس
اختر خدمة واحدة مهمة مثل checkout-service، وطبق auto-instrumentation و traces و metrics أساسية و Collector بسيط.
الهدف أن ترى أول trace حقيقي.
المرحلة الثانية: Collector مركزي
اجعل الخدمات ترسل إلى Collector:
checkout-service -> otel-collector -> tempo/prometheusأضف memory_limiter و batch و resource.
المرحلة الثالثة: Grafana Dashboards
ابن Dashboard تعرض request rate و error rate و p95 latency و top endpoints و traces البطيئة.
المرحلة الرابعة: Logs مع Traces
عدّل logging format ليشمل trace_id و span_id و service.name و deployment.environment.
المرحلة الخامسة: التوسع
أضف خدمات أخرى مثل auth و orders و payment و inventory، ثم راقب traces بين الخدمات.
المرحلة السادسة: Sampling و SLOs
عند زيادة البيانات، أضف sampling. وبعدها حول البيانات إلى أهداف reliability واضحة عبر SLOs.
مشروع عملي للتدريب
ابن نظاما صغيرا مكونا من:
- frontend بسيط
- orders-service
- payment-service
- inventory-service
- PostgreSQL
- Redis
- OpenTelemetry Collector
- Prometheus
- Grafana
- Tempo
- Loki
ثم نفذ السيناريوهات التالية:
- اجعل payment-service بطيئة عمدا.
- راقب latency في Grafana.
- افتح trace بطيء في Tempo.
- اربط trace_id مع log في Loki.
- أضف alert عندما p95 يتجاوز 1 ثانية.
- أضف sampling.
- أضف
service.versionوشاهد الفرق بعد deployment.
هذا المشروع ينقلك من الفهم النظري إلى خبرة عملية قوية.
أسئلة شائعة
هل أبدأ بـ Logs أم Metrics أم Traces؟
ابدأ بـ Metrics و Traces للخدمات المهمة، ثم اربط Logs بها. Metrics تعطيك الصورة العامة، Traces تعطيك رحلة الطلب، و Logs تعطيك التفاصيل الدقيقة.
هل OpenTelemetry مناسب فقط لـ Kubernetes؟
لا. يمكن استخدامه مع VM و Docker و Kubernetes و Serverless و Bare metal و Legacy systems. لكن أهميته تظهر بوضوح في الأنظمة الموزعة و Kubernetes.
هل أحتاج Collector دائما؟
في التجارب الصغيرة يمكنك الإرسال مباشرة إلى backend. في Production الأفضل استخدام Collector لأنه يعطيك مرونة وتحكما أكبر.
هل OpenTelemetry يحل محل APM tools؟
ليس تماما. OpenTelemetry يوفر standard لجمع وتصدير البيانات. أما APM tools فقد توفر storage و dashboards و alerting و service maps وتحليل متقدم.
مصطلحات مهمة
| المصطلح | المعنى |
|---|---|
| Telemetry | البيانات التي يخرجها النظام لفهم حالته |
| Observability | القدرة على فهم النظام من بياناته |
| Log | سجل نصي لحدث |
| Metric | رقم يقاس عبر الزمن |
| Trace | رحلة request داخل النظام |
| Span | خطوة واحدة داخل trace |
| Collector | وسيط يستقبل ويعالج ويصدر telemetry |
| Exporter | يرسل البيانات إلى backend |
| Receiver | يستقبل البيانات داخل Collector |
| Processor | يعالج البيانات داخل Collector |
| OTLP | بروتوكول OpenTelemetry |
| Instrumentation | تجهيز الكود لإنتاج telemetry |
| Semantic Conventions | أسماء موحدة للبيانات |
| Sampling | اختيار جزء من traces لتخزينه |
| Cardinality | عدد القيم المختلفة للـ label أو attribute |
| SLI | مؤشر قياس مستوى الخدمة |
| SLO | هدف مستوى الخدمة |
Roadmap لتعلم OpenTelemetry
المستوى الأول
- افهم Logs و Metrics و Traces.
- افهم الفرق بين Monitoring و Observability.
- شغل تطبيق بسيط مع auto-instrumentation.
- اعرض traces في Jaeger أو Tempo.
المستوى الثاني
- استخدم OpenTelemetry Collector.
- افهم receivers و processors و exporters.
- اربط metrics مع Prometheus.
- اعرض dashboards في Grafana.
المستوى الثالث
- استخدم Kubernetes.
- انشر Collector كـ Deployment أو DaemonSet.
- اربط logs بالـ traces.
- أضف resource attributes.
- ابدأ alerting.
المستوى الرابع
- طبق tail sampling.
- ابن SLOs.
- راقب Collector نفسه.
- عالج high cardinality.
- صمم observability architecture للشركة.
الخلاصة
OpenTelemetry أصبح من أهم المهارات الحديثة لمهندسي DevOps و SRE و Backend و Cloud، لأنه يحل مشكلة حقيقية: كيف نفهم أنظمتنا المعقدة في Production؟
في الأنظمة الحديثة لا يكفي أن تعرف أن الخدمة تعمل. يجب أن تعرف لماذا بطأت، لماذا فشلت، من تأثر، متى بدأ التأثير، وأي dependency تسبب بالمشكلة.
ابدأ صغيرا:
Service واحدة
Collector بسيط
Traces واضحة
Metrics أساسية
Logs مرتبطة بالـ trace_id
Dashboard مفيدةثم توسع تدريجيا. الهدف ليس جمع أكبر كمية من البيانات، بل جمع البيانات الصحيحة التي تساعدك على اتخاذ قرار سريع وقت المشكلة.


